































На щорічній конференції з систем обробки інформації для нейромереж (neurips) відбулася презентація двох найбільших у світі датасетів природної мови для ші-систем автоматичного транскрибування та перекладу.
Перший датасет називається people’s speech (»усне мовлення»). Він призначений для використання в ші-системах » автоматичного розпізнавання мови» і її транскрибування в текст.
Другий датасет отримав назву multilingual spoken words corpus (mswc) — »багатомовна мова». Він використовується для встановлення відповідності між односмисловими словоформами природної усної мови різних народів світу.
Розробка проектів people’s speech і mswc почалася в 2018 році. Ініціатором досліджень виступила асоціація ml commons, відома розробкою бенчмарків для ші-систем mlperf. Завданням дослідницьких проектів було виявлення та класифікація 50 найбільш активно використовуваних у світі розмовних мов. Результатом став набір примітивів. За наявними оцінками, створені дата-сети є найбільш повними серед усіх існуючих у світі, аналогічних наборів.
У розробці брали участь групи дослідників з intel, гарварду, alibaba, oracle, landing ai, мічиганського університету, google, baidu і ряду інших центрів.
Особливістю отриманих датасетів стало те, що при навчанні використовувалися дані з фоновим шумом і неформальними мовними оборотами в різних акустичних середовищах. Дослідники відразу відмовилися від застосування» ідеального » контенту, наприклад, аудіокниг, беручи до уваги, що неадаптований оригінальний контент дозволяє отримувати більш точні результати при реальному використанні навчених датасетов.
У датасет people’s speech входять десятки тисяч годин розмовних записів. В даний час це один з найбільших у світі наборів даних для розпізнавання усного мовлення англійською мовою. Він ліцензований для академічного та комерційного застосування та доступний для безкоштовного завантаження.
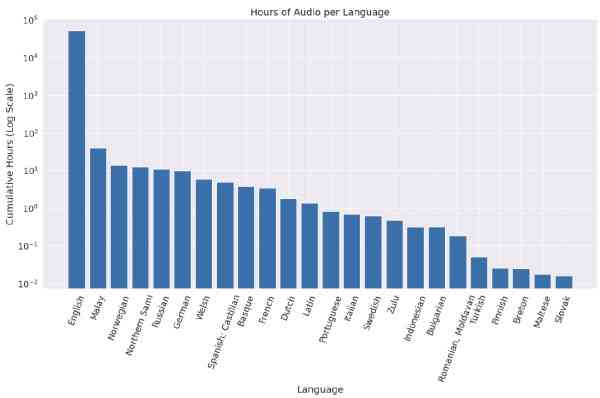
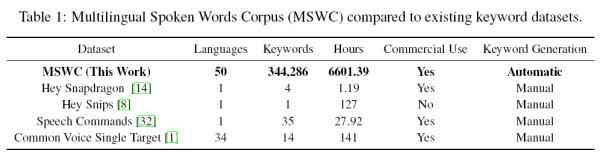
Набір аудіоречевих даних mswc містить понад 300 000 ключових слів на десятках мов світу. За даними intel, його аудиторія становить понад п’ять млрд осіб. Цей набір також має значні можливості для ліцензування, включаючи комерційне застосування.
Раніше редакція thg.ru опублікувала статтю про штучний інтелект . Штучний інтелект вже давно зайняв важливе місце в науково-фантастичній літературі і голлівудських блокбастерах. Саме вони формують думку більшості людей про те, що з себе представляє ші, і чого від нього слід очікувати. Але наскільки ця думка відповідає реальному стану речей? давайте розбиратися. Детальніше про це читайте в статті «штучний інтелект : правда і вигадка».
читайте також:

")
")











{kind=link}